
Authorization: Bad Implementation
Filed under: Development, Security, Testing
A few years ago, I joined a development team and got a chance to poke around a little bit for security issues. For a team that didn’t think much about security, it didn’t take long to identify some serious vulnerabilities. One of those issues that I saw related to authorization for privileged areas of the application. Authorization is a critical control when it comes to protecting your applications because you don’t want unauthorized users performing actions they should not be able to perform.
The application was designed using security by obscurity: that’s right, if we only display the administrator navigation panel to administrators, no one will ever find the pages. There was no authorization check performed on the page itself. If you were an administrator, the page displayed the links that you could click. If you were not an administrator, no links.
In the security community, we all know (or should know), that this is not acceptable. Unfortunately, we are still working to get all of our security knowledge into the developers’ hands. When this vulnerability was identified, the usual first argument was raised: "No hacker is going to guess the page names and paths." This is pretty common and usually because we don’t think of internal malicious users, or authorized individuals inadvertently sharing this information on forums. Lets not forget DirBuster or other file brute force tools that are available. Remember, just because you think the naming convention is clever, it very well can be found.
The group understood the issue and a developer was tasked to resolve the issue. Great.. We are getting this fixed, and it was a high priority. The problem…. There was no consultation with the application security guy (me at the time) as to the proposed solution. I don’t have all the answers, and anyone that says they do are foolish. However, it is a good idea to discuss with an application security expert when it comes to a large scale remediation to such a vulnerability and here is why.
The developer decided that adding a check to the Page_Init method to check the current user’s role was a good idea. At this point, that is a great idea. Looking deeper at the code, the developer only checked the authorization on the initial page request. In .Net, that would look something like this:
protected void Page_Init(object sender, EventArgs e) { if (!Page.IsPostBack) { //Check the user authorization on initial load if (!Context.User.IsInRole("Admin")) { Response.Redirect("Default.aspx", true); } } }
What happens if the user tricks the page into thinking it is a postback on the initial request? Depending on the system configuration, this can be pretty simple. By default, a little more difficult due to EventValidation being enabled. Unfortunately, this application didn’t use EventValidation.
There are two ways to tell the request that it is a postback:
- Include the __EVENTTARGET parameter.
- Include the __VIEWSTATE parameter.
So lets say we have an admin page that looks like the above code snippet, checking for admins and redirecting if not found. By accessing this page like so would bypass the check for admin and display the page:
http://localhost:49607/Admin.aspx?__EVENTTARGET=
This is an easy oversight to make, because it requires a thorough understanding of how the .Net framework determines postback requests. It gives us a false sense of security because it only takes one user to know these details to then determine how to bypass the check.
Lets be clear here, Although this is possible, there are a lot of factors that tie into if this may or may not work. For example, I have seen many pages that it was possible to do this, but all of the data was loaded on INITIAL page load. For example, the code may have looked like this:
protected void Page_Load(object sender, EventArgs e) { if (!Page.IsPostBack) { LoadDropDownLists(); LoadDefaultData(); } }
In this situation, you may be able to get to the page, but not do anything because the initial data needed hasn’t been loaded. In addition, EventValidation may cause a problem. This can happen because if you attempt a blank ViewState value it could catch that and throw an exception. In .Net 4.0+, even if EventValidation is disabled, ViewStateUserKey use can also block this attempt.
As a developer, it is important to understand how this feature works so we don’t make this simple mistake. It is not much more difficult to change that logic to test the users authorization on every request, rather than just on initial page load.
As a penetration tester, we should be testing this during the assessment to verify that a simple mistake like this has not been implemented and overlooked.
This is another post that shows the importance of a good security configuration for .Net and a solid understanding of how the framework actually works. In .Net 2.0+ EventValidation and ViewStateMac are enabled by default. In Visual Studio 2012, the default Web Form application template also adds an implementation of the ViewStateUserKey. Code Safe everyone.
2012 in Review
Filed under: Development, Security, Testing
Well here it is, 2012 is coming to an end and I thought I would wish everyone happy holidays, as well as mention some of the topics covered this year on my blog.
The year started out with a few issues in the ASP.Net framework. We saw a Forms Authentication Bypass that was patched at the very end of 2011 and an ASP.Net Insecure Redirect issue. Both of these issues show exactly why it is important to keep your frameworks patched.
Next, I did a lot of discussions about ViewStateMAC and EventValidation. This was some new stuff mixed in with some old. We learned that ViewStateMAC also protects the EventValidation field from being tampered with. I couldn’t find any MSDN documentation that states this fact. In addition, I showed how it is possible to manipulate the EventValidation field (when ViewStateMAC is not enabled) to tamper with the application. Here are some links to those posts:
- ViewStateMAC: Seriously, Enable It!
- ASP.Net: Tampering with Event Validation – Part 1
- ASP.Net: Tampering with Event Validation – Part 2
I also created the ASP.Net Webforms CSRF Workflow, which is a small diagram to determine possible CSRF vulnerabilities with an ASP.Net web form application.
The release of .Net 4.5 was fairly big and some of the enhancements are really great. One of those, was the change in how Request Validation works. Adding the ability for lazy validation increases the ability to limit what doesn’t get validated. In addition, ModSecurity was released for IIS.
The release of the Web.Config Security Analyzer happened early on in the year. It is a simple tool that can be used to scan a web.config file for common security misconfigurations.
Some other topics covered included .Net Validators (lets not forget the check for Page.IsValid), Forms Authentication Remember Me functionality, how the Request Method can matter, and a Request Validation Bypass technique.
I discussed how XSS can be performed by tampering with the ViewState and the circumstances needed for it to be possible. This is commonly overlooked by both developers and testers.
In addition, I have created a YouTube channel for creating videos of some of these demonstrations. There are currently two videos available, but look forward to more coming in 2013.
There is a lot to look forward to in 2013 and I can’t wait to get started. Look for more changes and content coming out of Jardine Software and its resources.
I hope everyone had a great year in 2012 and that 2013 brings better things to come.
ViewState XSS: What’s the Deal?
Filed under: Development, Security, Testing
Many of my posts have discussed some of the protections that ASP.Net provides by default. For example, Event Validation, ViewStateMac, and ViewStateUserKey. So what happens when we are not using these protections? Each of these have a different effect on what is possible from an attacker’s stand point so it is important to understand what these features do for us. Many of these are covered in prior posts. I often get asked the question “What can happen if the ViewState is not properly protected?â€Â This can be a difficult question because it depends on how it is not protected, and also how it is used. One thing that can possibly be exploited is Cross-site Scripting (XSS). This post will not dive into what XSS is, as there are many other resources that do that. Instead, I will show how an attacker could take advantage of reflective XSS by using unprotected ViewState.
For this example, I am going to use the most basic of login forms. The form doesn’t even actually work, but it is functional enough to demonstrate how this vulnerability could be exploited. The form contains a user name and password textboxes, a login button, and an asp.net label control that displays copyright information. Although probably not very obvious, our attack vector here is going to be the copyright label.
Why the Label?
You may be wondering why we are going after the label here. The biggest reason is that the developers have probably overlooked output encoding on what would normally be pretty static text. Copyrights do not change that often, and they are usually loaded in the initial page load. All post-backs will then just re-populate the data from the ViewState. That is our entry. Here is a quick look at what the page code looks like:
1: <asp:Content ID="BodyContent" runat="server" ContentPlaceHolderID="MainContent">
2: <span>UserName:</span><asp:TextBox ID="txtUserName" runat="server" />
3: <br />
4: <span>Password:</span><asp:TextBox ID="txtPassword" runat="server" TextMode="Password" />
5: <br />
6: <asp:Button ID="cmdSubmit" runat="server" Text="Login" /><br />
7: <asp:Label ID="lblCopy" runat="server" />
8: </asp:Content>
We can see on line 7 that we have the label control for the copyright data.  Here is the code behind for the page:
1: protected void Page_Load(object sender, EventArgs e)
2: {
3: if (!Page.IsPostBack)
4: {
5: lblCopy.Text = "Copy 2012 Test Company";
6: }
7: }
Here you can see that only on initial page load, we set the copy text. On Postback, this value is set from the ViewState.
The Attack
Now that we have an idea of what the code looks like, lets take a look at how we can take advantage of this. Keep in mind there are many factors that go into this working so it will not work on all systems.
I am going to use Fiddler to do the attack for this example. In most of my posts, I usually use Burp Suite, but there is a cool ViewState Decoder that is available for Fiddler that I want to use here. The following screen shows the login form on the initial load:
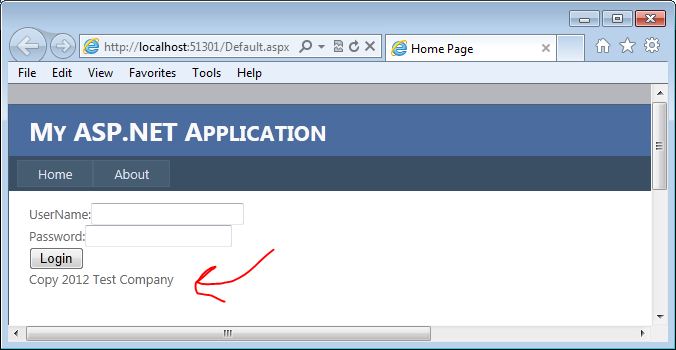
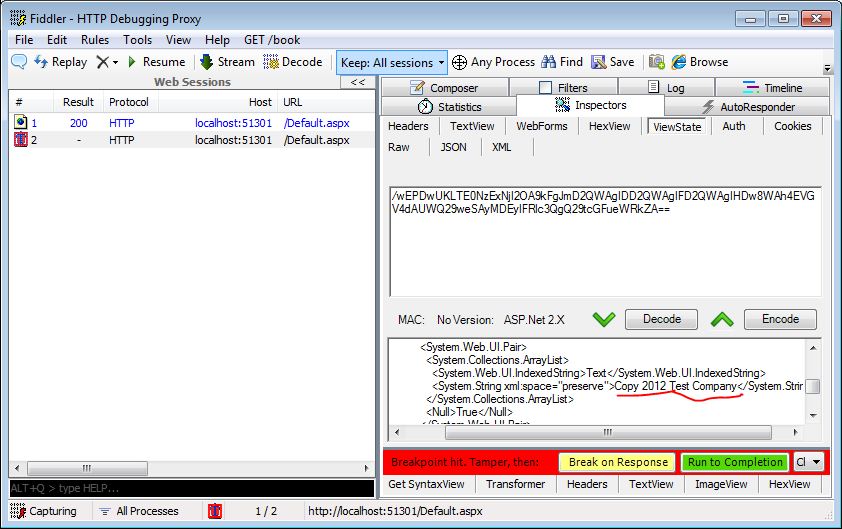
I will set up Fiddler to break before requests so I can intercept the traffic. When I click the login button, fiddler will intercept the request and wait for me to fiddle with the traffic. The next screen shows the traffic intercepted. Note that I have underlined the copy text in the view state decoder. This is where we are going to make our change.
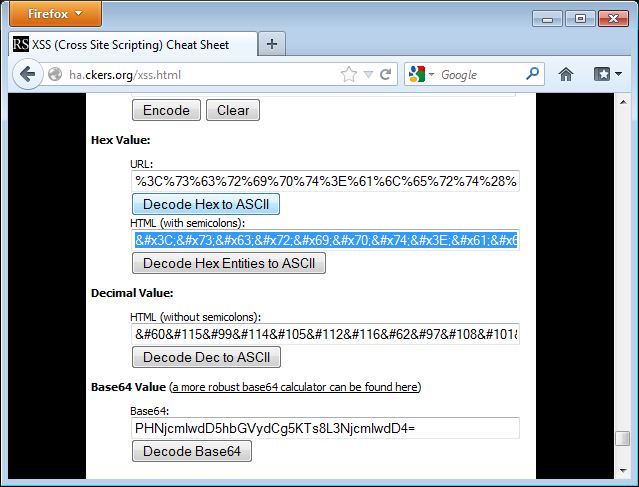
The attack will load in a simple alert box to demonstrate the presence of XSS. To load this in the ViewState Decoder’s XML format, I am going to encode the attack using HTML Entities. I used the encoder at http://ha.ckers.org/xss.html to perform the encoding. The following screen shows the data encoded in the encoder:
I need to copy this text from the encoder and paste it into the copy right field in the ViewState decoder window. The following image shows this being done:

Now I need to click the “Encode†button for the ViewState. This will automatically update the ViewState field for this request.  Once I do that, I can “Resume†my request and let it complete.  When the request completes, I will see the login page reload, but this time it will pop up an alert box as shown in the next screen:
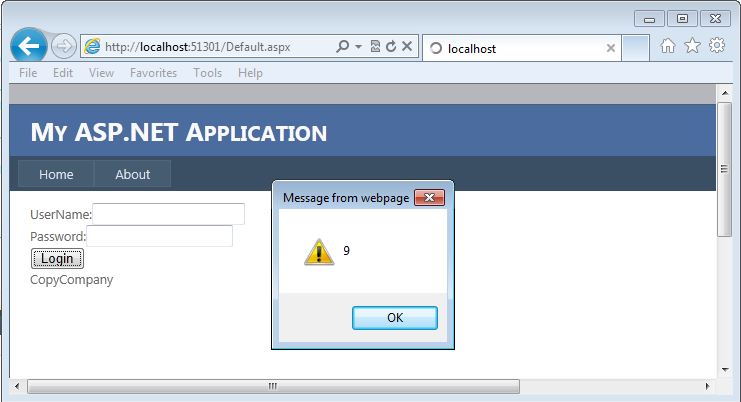
This shows that I was able to perform an XSS attack by manipulating a ViewState parameter. And as I mentioned earlier, this is reflected since it is being reflected from the ViewState. Win for the Attacker.
So What, I Can Attack Myself
Often times, when I talk about this technique, the first response is that the attacker could only run XSS against themselves since this is in the ViewState. How can we get that to our victim. The good news for the attacker…. .Net is going to help us attack our victims here. Without going into the details, the premise is that .Net will read the ViewState value from the GET or POST depending on the request method. So if we send a GET it will read it from the querystring.  So if we make the following request to the page, it will pull the ViewState values from the QueryString and execute the XSS just like the first time we ran it:
http://localhost:51301/Default.aspx?__VIEWSTATE=%2fwEPDwU
KLTE0NzExNjI2OA9kFgJmD2QWAgIDD2QWAgIFD2QWAgIHDw8WAh4
EVGV4dAUlQ29weTxzY3JpcHQ%2bYWxlcnQoOSk7PC9zY3JpcHQ%2b
Q29tcGFueWRkZA%3d%3d&ctl00%24MainContent%24txtUserName=
&ctl00%24MainContent%24txtPassword=
&ctl00%24MainContent%24cmdSubmit=Login
Since we can put this into a GET request, it is easier to send this out in phishing emails or other payloads to get a victim to execute the code. Yes, as a POST, we can get a victim to run this as well, but we are open to so much more when it is a GET request since we don’t have to try and submit a form for this to work.
How to Fix It
Developers can fix this issue quite easily. They need to encode the output for starters. For the encoding to work, however, you should set the value yourself on postback too. So instead of just setting that hard-coded value on initial page load, think about setting it every time. Otherwise the encoding will not solve the problem. Additionally, enable the built in functions like ViewStateMac, which will help prevent an attacker from tampering with the ViewState, or consider encrypting the ViewState.
Final Thoughts
This is a commonly overlooked area of security for .Net developers because there are many assumptions and mis-understandings about how ViewState works in this scenario. The complexity of configuration doesn’t help either. Many times developers think that since it is a hard-coded value.. it can’t be manipulated.  We just saw that under the right circumstances, it very well can be manipulated.
As testers, we need to look for this type of vulnerability and understand it so we can help the developers understand the capabilities of it and how to resolve it. As developers, we need to understand our development language and its features so we don’t overlook these issues. We are all in this together to help decrease the vulnerabilities available in the applications we use.
Updated [11/12/2012]: Uploaded a video demonstrating this concept.
Another Request Validation Bypass?
Filed under: Development, Security
I stumbled across this BugTraq(http://www.securityfocus.com/archive/1/524043) on Security Focus today that indicates another way to bypass ASP.Net’s built in Request Validation feature. It was reported by Zamir Paltiel from Seeker Research Center showing us how using a % symbol in the tag name (ex. <%tag>) makes it possible to bypass Request Validation and apparently some versions of Internet Explorer will actually parse that as a valid tag. Unfortunately, I do not have the specifics of which versions of IE will parse this. My feeble attempts in IE8 and IE9 did not succeed (and yes, I turned off the XSS filter). I did a previous post back in July of 2011 (which you can read here: https://jardinesoftware.net/2011/07/17/bypassing-validaterequest/) which discussed using Unicode-wide characters to bypass request validation.
I am not going to go into all the details of the BugTraq, please read the provided link as Zamir has done a great write up for it. Instead, I would like to talk about the proper way of dealing with this issue. Sure, .Net provides some great built in features, Event Validation, Request Validation, ViewStateMac, etc., but they are just helpers to our overall security cause. If finding out that there is a new way to bypass Request validation opens your application up to Cross-Site Scripting… YOU ARE DOING THINGS WRONG!!! Request Validation is so limited in its own nature that, although it is a nice-to-have, it is not going to stop XSS in your site. We have talked about this time and time again. Input Validation, Output Encoding. Say it with me: Input Validation, Output Encoding. Lets briefly discuss what we mean here (especially you.. the dev whose website is now vulnerable to XSS because you relied solely on Request Validation).
Input Validation
There are many things we can do with input validation, but lets not get too crazy here. Here are some common things we need to think about when doing input validation:
- What TYPE of data are we receiving. If you expect an Integer, then make sure that the value casts to an Integer. If you expect a date-time, then make sure it casts to a date time.
- How long should the data be. If you only want to allow 2 characters (state abbreviation?) then only allow 2 characters.
- Validate the data is in a specific range. If you have a numeric field, say an age, then validate that it is greater than 0 and less than 150, or whatever your business logic requires.
- Define a whitelist of characters allowed. This is big, especially for free-form text. If you only allow letters and numbers then only allow letters and numbers. This can be difficult to define depending on your business requirements. The more you add the better off you will be.
Output Encoding
I know a lot of people will disagree with me on this, but I personally believe that this is where XSS is getting resolved. Sure, we can do strict input validation on the front end. But what if data gets in our application some other way, say a rogue DBA or script running directly against the server. I will not get into all my feelings toward this, but know that I am all for implementing Input Validation. Now, on to Output Encoding. The purpose is to let the client or browser be able to distinguish commands from data. This is done by encoding command characters that the parser understands. For Example, for HTML the < character gets replaced with <. This tells the parser to display the less than character rather than interpret it as the start of a tag definition.
Even with all the input validation in the world, we must be encoding our output to protect against cross site scripting. It is pretty simple to do, although you do have to know what needs encoding and what does not. .Net itself makes this somewhat difficult since some controls auto encode data and others do not.
Can We Fix It?
With little hope that this will get resolved within the .Net framework itself, there are ways that we can update Request Validation ourselves, if you are using 4.0 or higher. Request Validation is Extensible, so it is possible to create your own class to add this check into Request Validation. I have included a simple PROOF OF CONCEPT!!! of attempting to detect this. THIS CODE IS NOT PRODUCTION READY and is ONLY FOR DEMONSTRATION PURPOSES.. USE AT YOUR OWN RISK!. ok enough of that. Below is code that will crudely look for the presence of the combination of <% in the request parameter. There are better ways of doing this, I just wanted to show that this can be done. Keep in mind, that if your application allows the submission of this combination of characters, this would probably not be a good solution. Alright.. the code:
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Web.Util; namespace WebTester { public class NewRequestValidation : RequestValidator { public NewRequestValidation() { } protected override bool IsValidRequestString( HttpContext context, string value, RequestValidationSource requestValidationSource, string collectionKey, out int validationFailureIndex) { validationFailureIndex = -1; // This check is not meant to be production code... // This is just an example of how to set up // a Request Validator override. // Please pick a better way of searching for this. if (value.Contains("<%")) // Look for <%... { return false; } else // Let the default Request Validtion take a look. { return base.IsValidRequestString( context, value, requestValidationSource, collectionKey, out validationFailureIndex); } } } }
In order to get a custom request validation override to work in your application, you must tell the application to use it in the web.config. Below is my sample web.config file updated for this:
<system.web>
<httpRuntime requestValidationType="WebTester.NewRequestValidation"/>
</system.web>
Conclusion
We, as developers, must stop relying on built in items and frameworks to protect us against security vulnerabilities. We must take charge and start practicing secure coding principles so that when a bug like this one is discovered, we can shrug it off and say that we are not worried because we are properly protecting our site.
Hopefully this will not affect many people, but I can assure you that you will start seeing this being tested during authorized penetration tests and criminals. The good news, if you are protected, is that it is going to waste a little bit of the attacker’s time by trying this out. The bad news, and you know who I am talking about, is that your site may now be vulnerable to XSS. BTW, if you were relying solely on Request Validation to protect your site against XSS, you are probably already vulnerable.
Request Method Can Matter
Filed under: Development, Security
One of the nice features of ASP.Net is that many of the server controls populate their values based upon the request method. Lets look at a quick example. If the developer has created a text box on the web form, called txtUserName, then on a post back the Text property will be populated from the proper request collection based on the request method. So if the form was sent via a GET request, then txtUserName.Text is populated from Request.QueryString[“txtUserNameâ€]. If the form was sent via a POST request, then txtUserName.Text is populated from Request.Form[“txtUserNameâ€]. I know, master pages and other nuances may change the actual name of the client id, but hopefully you get the point.
GET REQUEST
txtUserName.Text = Request.QueryString[“txtUserNameâ€]
POST REQUEST
txtUserName.Text = Request.Form[“txtUserNameâ€]
Although this is very convenient for the developer, there are some concerns on certain functionality that should be considered. Think about a login form. One of the security rules we always want to follow is to never send sensitive information in the URL. With that in mind, the application should not allow the login form to be submitted using a GET request because the user name and password would be passed via the query string. By default, most login forms will accept both GET and POST requests because of how the framework and server controls work. Why would someone use a get request? Automation? Easy login, think for example if I craft the proper URL and bookmark the login page so it auto logs me in to the site. Although not very common we, as developers, have to protect our users from abusing this type of flaw. In no way am I saying not to use the server controls.. they are great controls. The point is to be aware of the pitfalls in some situations.
The good news!! We just need to check the request method and only accept POST requests. If we receive a GET request, just reject it. Yes, a user can still submit the GET request, but it won’t authenticate them and defeats the purpose of the user. Lets take a moment to look at some code that uses the default functionality.
Below is a VERY simple method that demonstrates how both GET and POST requests act. Although it is not anything more than Response.Write calls, it is sufficient to demonstrate the point.
protected void Page_Load(object sender, EventArgs e) { if (Page.IsPostBack) { // Encode the Value from the TextBox Response.Write(HttpUtility.HtmlEncode(txtUserName.Text)); Response.Write(":"); // Encode the value from the TextBox Response.Write(HttpUtility.HtmlEncode(txtPassword.Text)); } }
Here is a POST Request:
POST http://localhost:60452/Default.aspx HTTP/1.1 Accept: text/html, application/xhtml+xml, */* Referer: http://localhost:60452/Default.aspx Accept-Language: en-US User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0) Content-Type: application/x-www-form-urlencoded Accept-Encoding: gzip, deflate Host: localhost:60452 Content-Length: 316 Connection: Keep-Alive Pragma: no-cache Cookie: .ASPXANONYMOUS=YQOZB3SHzQEkAAAANDE 4NDczYzctZjVmNi00ZWEzLWJkYTMtZDZjYmZhN zY0Y2MylOoTQwCvDTUzA6LJuOO33witVabGXV 4RoXUeyg52RDY1; ASP.NET_SessionId=jkne3su2dwemw0lu1kqbjrdq __VIEWSTATE=%2FwEPDwUJNjk1NzE5OTc4ZGRjhRm%2FtVkqPqFadKC IAA0lQHoBH0FsR4xVM%2FiTGn7Sew%3D%3D&__EVENTVALIDATION=%2 FwEWBALk1bPACQKMrfuqAgKOsPfSCQKP5u6DCONM%2B3R6i2D%2 FIRsWvIhZp5wqldnzoa%2BjoUVRrng5kifu&ctl00%24 MainContent%24txtUserName=jjardine&ctl00%24MainContent%24 txtPassword=password&ctl00%24MainContent%24cmdSubmit=
The application will write out “jjardine:password†to the browser. This makes sense since those two values were passed. Now lets take a look at a GET Request and see the same request:
http://localhost:60452/Default.aspx?__VIEWSTATE=%2FwEPDwUJNjk1N
zE5OTc4ZGRjhRm%2FtVkqPqFadKCIAA0lQHoBH0FsR4xVM%2FiTGn7Sew
%3D%3D&__EVENTVALIDATION=%2FwEWBALk1bPACQKMrfuqAgKOsP
fSCQKP5u6DCONM%2B3R6i2D%2FIRsWvIhZp5wqldnzoa%2BjoUVRrng
5kifu&ctl00%24MainContent%24txtUserName=jjardine
&ctl00%24MainContent%24txtPassword=password&
ctl00%24MainContent%24cmdSubmit=
Again, this output will write out “jjardine:password†to the browser. The big difference here is that we are sending sensitive information in the URL which, as mentioned above, is a big no-no. We can’t stop a user from submitting a request like this. However, we can decide to not process it which should be enough to get someone to stop doing it.
It is important to note that any form that has sensitive information and uses the server controls like this can be vulnerable to this issue. There are some mitigations that can be put in place.
Check the Request Method
It is very easy to check the request method before processing an event. The below code shows how to implement this feature:
protected void Page_Load(object sender, EventArgs e) { if (Page.IsPostBack) { if (Request.RequestType == "POST") { // Encode the Value from the TextBox Response.Write(HttpUtility.HtmlEncode(txtUserName.Text)); Response.Write(":"); // Encode the value from the TextBox Response.Write(HttpUtility.HtmlEncode(txtPassword.Text)); } } }
Now, if the request is not a POST, it will not process this functionality. Again, this is a very simplistic example.
Implement CSRF Protection
Implementing CSRF protection is beyond the scope of this post, but the idea is that there is something unique about this request per the user session. As we saw in the GET request example, there are more parameters than just the user name and password. However, in that example, these fields are all static. There is no randomness. CSRF protection adds randomness to the request so even if the user was able to send a get request, their next session attempt would no longer work because of this missing random value.
Large Data
So large data doesn’t sound like a lot here, but it is a mitigation based on the construction of the page. If the viewstate and other parameters become really long, then they will be too large to put in the URL (remember this is usually limited on length). If that is the case, the user will not be able to send all the parameters required and will be blocked. This is usually not the case on login pages as there is usually very little data that is sent. The viewstate is usually not that big so make sure you are aware of those limits.
Why do we care?
Although this may not really seem like that big of an issue, it does pose a risk to an application. Due to compliance reasons related to storing sensitive information in log files, doing our part in protecting users data (especially authentication data), and the fact that this WILL show up on penetration testing reports, this is something that should be investigated. As you can see, it is not difficult to resolve this issue, especially for the login screen.
In addition to the login screen, if other forms are set up to support both GETS and POSTS, it could make CSRF attacks easier as well. Although we can do a CSRF attack with a POST request, a GET can be deployed in more ways. This risk is often overlooked, but is an easy win for developers to implement. Happy Coding!!
ModSecurity released for IIS
It was just announced on Microsoft Technet that a ModSecurity extension is now available for IIS. While this is still in Release Candidate status, a stable release is expected soon. There are standard MSI installers for IIS 7 and later versions on Source Forge. For the full write-up please visit the Microsoft Research site here: http://blogs.technet.com/b/srd/archive/2012/07/26/announcing-the-availability-of-modsecurity-extension-for-iis.aspx
ModSecurity is an open source web application firewall that can be implemented to help provide protection for your web applications. It has long been available on other platforms, such as apache, and is finally available for IIS. You can learn more about ModSecurity here: http://www.modsecurity.org/
I have a feeling a lot more info is going to be coming in regards to using ModSecurity with IIS.
Handling Request Validation Exceptions
Filed under: Development
I write a lot about the request validation feature built into .Net because I believe it serves a great purpose to help reduce the attack surface of a web application. Although it is possible to bypass it in certain situations, and it is very limited to HTML context cross site scripting attacks, it does provide some built in protection. Previously, I wrote about how request validation works and what it is ultimately looking for. Today I am going to focus on some different ways that request validation exceptions can be handled.
No Error Handling
How many times have you seen the “Potentially Dangerous Input” error message on an ASP.Net application? This is a sure sign to the user that the application has request validation enabled, but that the developers have not taken care to provide friendly error messages. Custom Errors, which is enabled by default, should even hide this message. So if you are seeing this, there is a good chance there are other configuration issues with the site. The following image shows a screen capture of this error message:
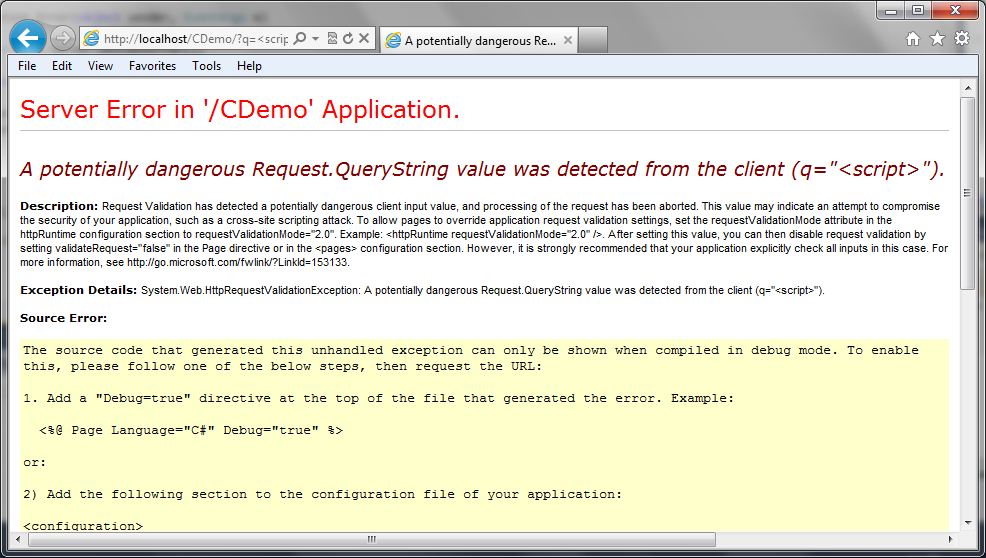
This is obviously not the first choice in how we want to handle this exception. For one, it gives out a lot of information about our application and it also provides a bad user experience. Users want to have error messages (no one really wants error messages) that match the look and feel of the application.
Custom Errors
ASP.Net has a feature called “Custom Errors” which is the final catch in the framework for exceptions within an ASP.Net application. If the developer hasn’t handled the exception at all, custom errors picks it up (that is, if it is enabled (default)). Just enabling customer errors is a good idea. If we just set the mode to “On” we get a less informative error message, but it still doesn’t look like the rest of the site.
The following code snippet shows what the configuration looks like in the web.config file:
<system.web>
<customErrors mode="On" />
The following screen shot shows how this looks:
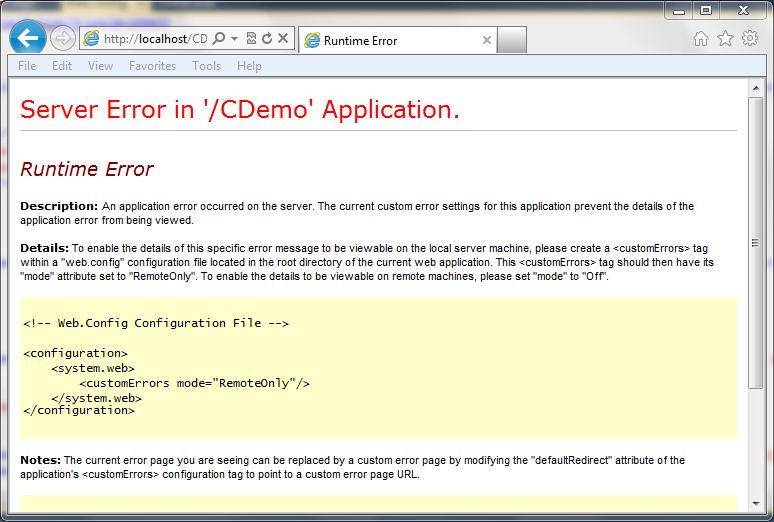
Custom Errors with Redirect
Just turning customer errors on is helpful, but it is also possible to redirect to a generic error page. This allows the errors to go to a page that contains a generic error message and can look similar to how the rest of the site looks. The following code snippet shows what the configuration looks like in the web.config file:
<system.web>
<customErrors mode="On" defaultRedirect="Error.aspx" />
The screen below shows a generic error page:
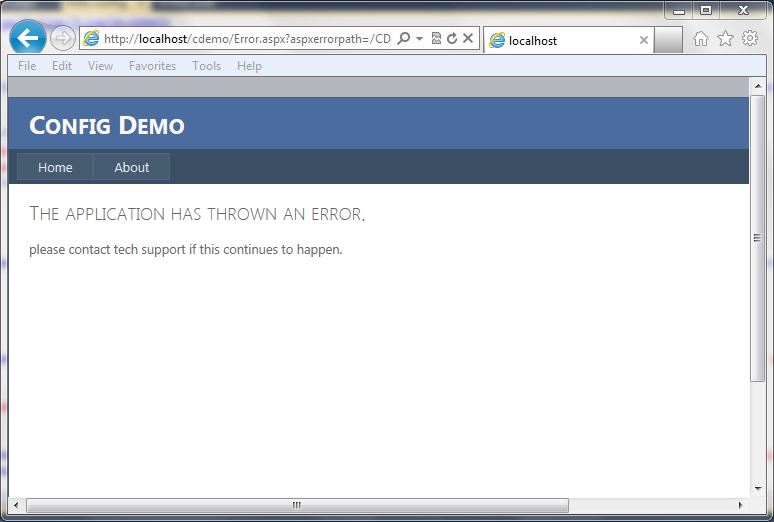
Custom Error Handling
If you want to get really specific with handling the exception, you can add some code to the global.asax file for the application error event. This allows determing the type of exception, in this case the HTTPRequestValidationException, and redirecting to a more specific error page. The code below shows a simple way to redirect to a custom error page:
void Application_Error(object sender, EventArgs e)
{
Exception ex = Server.GetLastError();
if (ex is HttpRequestValidationException)
{
Server.ClearError();
Response.Redirect("RequestValidationError.aspx", false);
}
}
Once implemented, the user will get the following screen (again, this is a custom screen for this application, you can build it however you like):

As you can see, there are many ways that we can handle this exception, and probably a few more. This is just an example of some different ways that developers can help make a better user experience. The final example screen where it lists out the characters that are triggering the exception to occur could be considered too much information, but this information is already available on the internet and previous posts. It may not be very helpful to most users in the format I have displayed it in, so make sure that the messages you provide to the users are in consideration of their understanding of technology. In most cases, just a generic error message is acceptable, but in some cases, you may want to provide some specific feedback to your users that certain data is not acceptable. For example, the error message could just state that the application does not accept html characters. At the very least, have custom errors enabled with a default error page set so that overly verbose, ugly messages are not displayed back to the user.
Forms Authentication: Remember Me? Its Hard Not Too!
Filed under: Development, Security
ASP.Net Forms Authentication is a great way to authenticate users for the application. Microsoft has done a really good job at implementing this to make it simple and straightforward for developers. Forms Authentication allows for a user to enter their user name / password combination for an application and have that validated against a backend data source. There are some built in providers to help make this a pretty seamless and painless process for developers. The basic workflow for forms authentication is:
- User attempts to access a resource (details.aspx).
- Server requires the user to be authenticated and redirects the user to the login page (login.aspx).
- User enters user name and password and submits these to the server.
- Server Validates the credentials and if valid, creates an authentication cookie (most common) and sends it back to the user.
- With valid cookie, user no longer needs to enter a user name and password to access the site on each page request.
The key point here is that, after initial login, only the authentication cookie is needed to access the site. In most cases, this cookie is non-persistent, meaning it will get deleted after the session has ended or the browser is closed. In addition, the forms authentication cookie is httpOnly by default, which is meant to limit client side script from accessing it.
Remember Me?
ASP.Net Forms Authentication has a feature to allow the application to “Remember Me.†this is seen on many login screens under the password box. By default, the only thing this built in checkbox does is determine if the authentication cookie should be persistent or non-persistent. When the checkbox is checked, the cookie will be persistent and live on after the browser is closed until it expires according to its timeout property.
From a security standpoint, it is usually not recommended for an application to allow automatic login in this way. What if someone else uses your computer or maliciously takes it over. In either of these cases, all they have to do is navigate to the application and they will be logged back into the application as the original user with no requirement for a password. To add some salt to the wound, many sites that implement the “Remember Me†functionality set the timeout to days, months, or even years.
Unfortunately, there doesn’t appear to be any easy way to change the default functionality of the “Remember Me†feature. For example, it might be more convenient to have the application just remember the user’s user name, and just require them to enter their password. From a security perspective, there could be an argument made that this is also taboo, but it is certainly better than not requiring anything. In order to achieve this, it would require custom code basically set up to replace the default remember me checkbox, or override its functionality. It is too bad that the build in functionality doesn’t have a property on it to determine if it is remembering everything, or just the user name.
Its Hard Not Too!
Now that “Remember Me†has been covered, lets dig a little deeper into the Forms Authentication Cookie (token). There is something important to know about a forms authentication token, the actual value stored in the cookie. The token has a built in timeout, and IT IS VALID until that timeout is reached. There is really no good way to kill a forms authentication token before its timeout period. Upon logout, you can call FormsAuthentication.Signout(), but the only thing this method does is remove the cookie from the browser. You may ask what the problem is if the cookie has been removed. The issue occurs if someone has been able to get that token before it was removed. It is beyond the scope of this post to discuss the ways that this could be done, but it can be done.
If someone access the token, they have free reign to use it, as long as the internal timeout has not expired. This is exactly why it is important to set a low timeout value. If the timeout is low, there is a smaller window if a user to use that token to attempt to keep it alive. With a large timeout, if an attacker got their hands on that token, they are good to login for the life of that token, or until you change your machine keys which may invalidate that token. This is a serious limitation of the token that developers need to be aware of.
There are many different ways that developers implement their authentication and authorization. Although this token can live longer than expected, at the least, it may just say you are authenticated. At the most, it could allow full compromise of the user’s account. For example, if the application additionally uses session state to validate if a user is valid then this would not be an issue because just randomly using the token on a new session would fail. There are many ways to handle this issue, the point is that we all need to be aware of how this token works so we can be prepare for the downsides.
.Net Validators – Don’t Forget Page.IsValid
Filed under: Development, Security
ASP.net does a good job of providing a simple way to provide input validation. Just about any security presentation or class will put a lot of emphasis on the concept of input validation. One of the techniques that you can use with web forms is the built in validator controls. In general, these controls automatically provide both client and server side validation, with the exception of the custom validator. It is important to understand that the client side validation is only there for convenience and to provide a more flowing user interface. In no way should client side validation be used for security because it can easily be bypassed by using a proxy tool. Lets take a look at a really simple example of a required field validator control on a textbox. Here is the simple html:
1: <div>
2: <asp:Label ID="lblText" runat="server" Text="Input:" />
3: <asp:TextBox CausesValidation="true" ID="txtText" runat="server" />
4: <asp:RequiredFieldValidator ID="rfvText" runat="server"
5: ControlToValidate="txtText" ErrorMessage="Field is required"
6: Display="Dynamic" />
7: <asp:Button ID="cmdSubmit" runat="server" Text="Submit"
8: onclick="cmdSubmit_Click" />
9: </div>
On line 3, there is a textbox that is used for user input. On line 4, a RequiredFieldValidator control was used to ensure that this field is required. There are many different properties for this control, however we have just set the minimum fields. ControltoValidate describes the control we actually want to require. The ErrorMessage is the message that will be displayed when the field is empty. The following image shows what it would look like if you clicked the “Submit” button when the field is empty. Notice that there is a red message that says “Field is required.” This request never even made it to the server because of the client side validation performed.
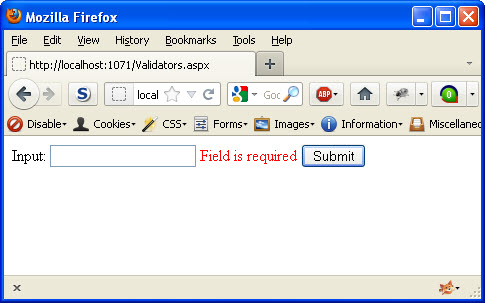
As mentioned previously, relying on the client side validation is not enough for the security of our application. In this example, I will use Burp Suite to bypass the client side validation and submit an empty value for the textbox. To do this, I just submit an actual string for the textbox, but intercept the request with Burp. When I intercept it, I will then remove the value for the textbox. At this point, I have bypassed the client side validation. Before we take a look at the server side validation, lets show what should happen when the submit button is clicked.
protected void cmdSubmit_Click(object sender, EventArgs e)
{
Response.Write("The button was clicked and is Valid.");
}
The above code is overly simplistic, but it will work to show how this works. When the button is clicked, it should only show this message when the textbox has data in it.. At least that was our idea when we put our validator control on the form. So lets take a look at what happens when we bypass the client side validation.
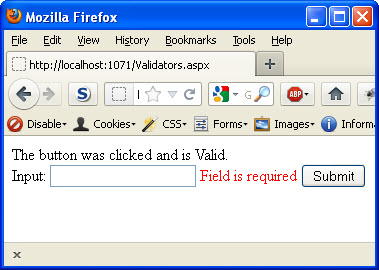
What happened? Not only did our button code execute (we see the output message), but our validation also shows an error message. This has to do with how the validation controls work. For most events, the page will execute the Page.Validate method which runs the validation routine for all controls for that event. This, however, does not throw errors within the system. It is up to the developer to actually check to determine if the validation is valid for the page or not. To fix this issue, we can simply update our code to check Page.IsValid before performing any actions in our button event.
protected void cmdSubmit_Click(object sender, EventArgs e)
{
if (!Page.IsValid)
{
return;
}
Response.Write("The button was clicked and is Valid.");
}
The above code shows how the first thing we check in the button click event is whether or not the page is valid. If any validator that was checked had an error then this would be false and we would not execute our button event. Often times, developers overlook checking this property. This oversight can turn your validator controls into virtual paper weights. Now the output will look as we expect again.
This example shows an overly simplistic use of the validator controls and only touches on the required field validator. This information is the same for all of the validator controls. If you are using validators, make sure you are calling Page.IsValid.
WCSA – Web.Config Security Analyzer
Filed under: Development
In an ASP.Net application, the web.config file contains a lot of security settings that shouldn’t be overlooked. There has been no real easy way to review the file without manually looking at each setting or running an expensive tool. To fill this gap, WCSA was born. This initial release is relatively simple and by no means covers all of the security settings for a web.config file. It does, however, cover some of the more prominent issues. BTW, the tool is free!!. Let me make it perfectly clear that this is the initial release of this tool and there is no claim that it will find all security issues for the web.config file or a given application. This tool helps identify potential issues but manual reviews should also be performed.
No Frills
The initial release of this application is very simple. There are no fancy UI components and the rule set is pretty limited. The goal is to make updates to this to add more rule sets and functionality. For now, it is a 5 minute process for developers to get a quick look at some of the settings without having to scan the web.config file looking for them.
The Application
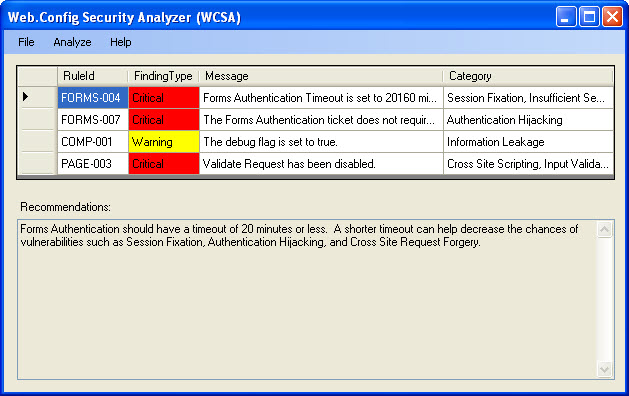
As you can see in Image 1 below, the application is pretty simple. This image shows the results of scanning a web.config file and the findings from the tool. There are currently 3 finding types (Information,Warning,Critical) based on their potential severity. Some poor color coding was added to help identify the risks by severity. Each finding has a Message that gives a brief description of the issue and the possible category of vulnerability that this could fall under. If you select a specific finding, some more information is displayed in the Recommendations section at the bottom of the screen.
Image 1
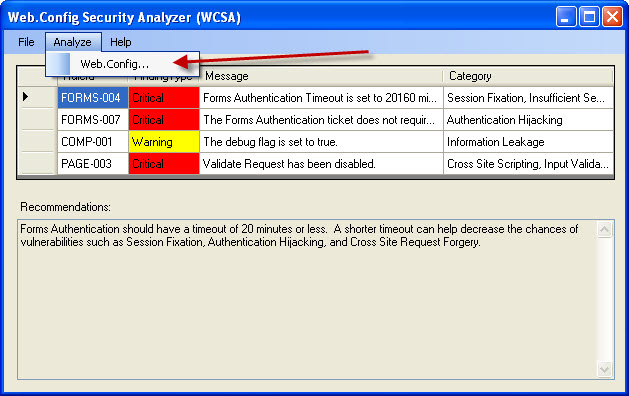
Lets walk through the simple steps of analyzing a web.config file. In the first step, we need to select Analyze—>Web.Config from the main menu.
Next, we select the Web.config file that we want to analyze.

The result is what we saw in Image 1 above. The file has been analyzed. If you want, you can export the results to an XML file by clicking the File->Export->To XML menu item.
Current Rules
The application currently checks the following elements:
- Compilation
- Custom Errors
- Forms Authentication
- Identity
- Pages
- Runtime
- Session
- Trace
I am currently working on more specific documentation on each rule covered and adding more elements to be scanned.
WCSA can be downloaded from here: http://www.jardinesoftware.com/Software/WCSA_1_0_0.zip. To run the application, just unzip the file and execute the WCSAWin.exe file.
To visit the WCSA information page, go to: http://www.jardinesoftware.com/WCSA.
This information is provided as-is and is for educational purposes only. There is no claim to the accuracy of this data. Use this information at your own risk. Jardine Software is not responsible for how this data is used by other parties.
Follow Us


