
What is the difference between encryption and hashing?
Filed under: Development, Security
Encryption is a reversible process, whereas hashing is one-way only. Data that has been encrypted can be decrypted back to the original value. Data that has been hashed cannot be transformed back to its original value.
Encryption is used to protect sensitive information like Social Security Numbers, credit card numbers or other sensitive information that may need to be accessed at some point.
Hashing is used to create data signatures or comparison only features. For example, user passwords used for login should be hashed because the program doesn’t need to store the actual password. When the user attempts to log in, the system will generate a hash of the supplied password using the same technique as the one stored and compare them. If they match, the passwords are the same.
Another example scenario with hashing is with file downloads to verify integrity. The supplier of the file will create a hash of the file on the server so when you download the file you can then generate the hash locally and compare them to make sure the file is correct.
XmlSecureResolver: XXE in .Net
Filed under: Development, Security, Testing
tl;dr
- Microsoft .Net 4.5.2 and above protect against XXE by default.
- It is possible to become vulnerable by explicitly setting a XmlUrlResolver on an XmlDocument.
- A secure alternative is to use the XmlSecureResolver object which can limit allowed domains.
- XmlSecureResolver appeared to work correctly in .Net 4.X, but did not appear to work in .Net 6.
I wrote about XXE in .net a few years ago (https://www.jardinesoftware.net/2016/05/26/xxe-and-net/) and I recently starting doing some more research into how it works with the later versions. At the time, the focus was just on versions prior to 4.5.2 and then those after it. At that time there wasn’t a lot after it. Now we have a few versions that have appeared and I started looking at some examples.
I stumbled across the XmlSecureResolver class. It peaked my curiosity, so I started to figure out how it worked. I started with the following code snippet. Note that this was targeting .Net 6.0.
static void Load()
{
string xml = "<?xml version='1.0' encoding='UTF-8' ?><!DOCTYPE foo [<!ENTITY xxe SYSTEM 'https://labs.developsec.com/test/xxe_test.php'>]><root><doc>&xxe;</doc><foo>Test</foo></root>";
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.XmlResolver = new XmlSecureResolver(new XmlUrlResolver(), "https://www.jardinesoftware.com");
xmlDoc.LoadXml(xml);
Console.WriteLine(xmlDoc.InnerText);
Console.ReadLine();
}So what is the expectation?
- At the top of the code, we are setting some very simple XML
- The XML contains an Entity that is attempting to pull data from the labs.developsec.com domain.
- The xxe_test.php file simply returns “test from the web..”
- Next, we create an XmlDocument to parse the xml variable.
- By Default (after .net 4.5.1), the XMLDocument does not parse DTDs (or external entities).
- To Allow this, we are going to set the XmlResolver. In This case, we are using the XmlSecureResolver assuming it will help limit the entities that are allowed to be parsed.
- I will set the XmlSecureResolver to a new XmlUrlResolver.
- I will also set the permission set to limit entities to the jardinesoftware.com domain.
- Finally, we load the xml and print out the result.
My assumption was that I should get an error because the URL passed into the XmlSecureResolver constructor does not match the URL that is referenced in the xml string’s entity definition.
https://www.jardinesoftware.com != https://labs.developsec.com
Can you guess what result I received?
If you guessed that it worked just fine and the entity was parsed, you guessed correct. But why? The whole point of XMLSecureResolver is to be able to limit this to only entities from the allowed domain.
I went back and forth for a few hours trying different configurations. Accessing different files from different locations. It worked every time. What was going on?
I then decided to switch from my Mac over to my Windows system. I loaded up Visual Studio 2022 and pulled up my old project from the old blog post. The difference? This project was targeting the .Net 4.8 framework. I ran the exact same code in the above snippet and sure enough, I received an error. I did not have permission to access that domain.
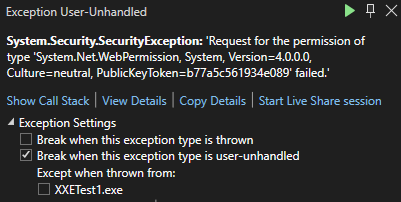
Finally, success. But I wasn’t satisfied. Why was it not working on my Mac. So I added the .Net 6 SDK to my Windows system and changed the target. Sure enough, no exception was thrown and everything worked fine. The entity was parsed.
Why is this important?
The risk around parsing XML like this is a vulnerability called XML External Entities (XXE). The short story here is that it allows a malicious user to supply an XML document that references external files and, if parsed, could allow the attacker to read the content of those files. There is more to this vulnerability, but that is the simple overview.
Since .net 4.5.2, the XmlDocument object was protected from this vulnerability by default because it sets the XmlResolver to null. This blocks the parser from parsing any external entities. The concern here is that a user may have decided they needed to allow entities from a specific domain and decided to use the XmlSecureResolver to do it. While that seemed to work in the 4.X versions of .Net, it seems to not work in .Net 6. This can be an issue if you thought you were good and then upgraded and didn’t realize that the functionality changed.
Conclusion
If you are using the XmlSecureResolver within your .Net application, make sure that it is working as you expect. Like many things with Microsoft .Net, everything can change depending on the version you are running. In my test cases, .Net 4.X seemed to work properly with this object. However, .Net 6 didn’t seem to respect the object at all, allowing DTD parsing when it was unexpected.
I did not opt to load every version of .Net to see when this changed. It is just another example where we have to be conscious of the security choices we make. It could very well be this is a bug in the platform or that they are moving away from using this an a way to allow specific domains. In either event, I recommend checking to see if you are using this and verifying if it is working as expected.
Input Validation for Security
Filed under: Development, Security
Validating input is an important step for reducing risk to our applications. It might not eliminate the risk, and for that reason we should consider what exactly we are doing with input validation.
Should you be looking for every attack possible?
Should you create a list of every known malicious payload?
When you think about input validation are you focusing on things like Cross-site Scripting, SQL Injection, or XXE, just to name a few? How feasible is it to attempt to block all these different vulnerabilities with input validation? Are each of these even a concern for your application?
I think that input validation is important. I think it can help reduce the ability for many of these vulnerabilities. I also think that our expectation should be aligned with what we can be doing with input validation. We shouldn’t overlook these vulnerabilities, but instead realize appropriate limitations. All of these vulnerabilities have a counterpart, such as escaping, output encoding, parser configurations, etc. that will complete the appropriate mitigation.
If we can’t, or shouldn’t, block all vulnerabilities with input validation, what should we focus on?
Start with focusing on what is acceptable data. It might be counter-intuitive, but malicious data could be acceptable data from a data requirements statement. We define our acceptable data with specific constraints. These typically fall under the following categories:
* Range – What are the bounds of the data? ex. Age can only be between 0 and 150.
* Type – What type of data is it? Integer, Datetime, String.
* Length – How many characters should be allow?
* Format – Is there a specific format? Ie. SSN or Account Number
As noted, these are not specifically targeting any vulnerability. They are narrowing the capabilities. If you verify that a value is an Integer, it is hard to get typical injection exploits. This is similar to custom format requirements. Limiting the length also restricts malicious payloads. A state abbreviation field with a length of 2 is much more difficult to exploit.
The most difficult type is the string. Here you may have more complexity and depending on your purpose, might actually have more specific attacks you might look for. Maybe you allow some HTML or markup in the field. In that case, you may have more advanced input validation to remove malicious HTML or events.
There is nothing wrong with using libraries that will help look for malicious attack payloads during your input validation. However, the point here is to not spend so much time focusing on blocking EVERYTHING when that is not necessary to get the product moving forward. Understand the limitation of that input validation and ensure that the complimenting controls like output encoding are properly engaged where they need to be.
The final point I want to make on input validation is where it should happen. There are two options: on the client, or on the server. Client validation is used for immediate feedback to the user, but it should never be used for security.
It is too easy to bypass client-side validation routines, so all validation should also be checked on the server. The user doesn’t have the ability to bypass controls once the data is on the server. Be careful with how you try to validate things on the client directly.
Like anything we do with security, understand the context and reasoning behind the control. Don’t get so caught up in trying to block every single attack that you never release. There is a good chance something will get through your input validation. That is why it is important to have other controls in place at the point of impact. Input validation limits the amount of bad traffic that can get to the important functions, but the functions still may need to do additional processes to be truly secure.
SQL Injection: Calling Stored Procedures Dynamically
Filed under: Development, Security, Testing
It is not news that SQL Injection is possible within a stored procedure. There have been plenty of articles discussing this issues. However, there is a unique way that some developers execute their stored procedures that make them vulnerable to SQL Injection, even when the stored procedure itself is actually safe.
Look at the example below. The code is using a stored procedure, but it is calling the stored procedure using a dynamic statement.
conn.Open();
var cmdText = "exec spGetData '" + txtSearch.Text + "'";
SqlDataAdapter adapter = new SqlDataAdapter(cmdText, conn);
DataSet ds = new DataSet();
adapter.Fill(ds);
conn.Close();
grdResults.DataSource = ds.Tables[0];
grdResults.DataBind();
It doesn’t really matter what is in the stored procedure for this particular example. This is because the stored procedure is not where the injection is going to occur. Instead, the injection occurs when the EXEC statement is concatenated together. The email parameter is being dynamically added in, which we know is bad.
This can be quickly tested by just inserting a single quote (‘) into the search field and viewing the error message returned. It would look something like this:
System.Data.SqlClient.SqlException (0x80131904): Unclosed quotation mark after the character string ”’. at System.Data.SqlClient.SqlConnection.OnError(SqlException exception, Boolean breakConnection, Action`1 wrapCloseInAction) at System.Data.SqlClient.SqlInternalConnection.OnError(SqlException exception, Boolean breakConnection, Action`1 wrapCloseInAction) at System.Data.SqlClient.TdsParser.ThrowExceptionAndWarning(TdsParserStateObject stateObj, Boolean callerHasConnectionLock, Boolean asyncClose) at System.Data.SqlClient.TdsParser.TryRun(RunBehavior runBehavior, SqlCommand cmdHandler, SqlDataReader dataStream, BulkCopySimpleResultSet bulkCopyHandler, TdsParserStateObject stateObj, Boolean& dataReady) at System.Data.SqlClient.SqlDataReader.TryConsumeMetaData() at System.Data.SqlClient.SqlDataReader.get_MetaData() at
With a little more probing, it is possible to get more information leading us to understand how this SQL is constructed. For example, by placing ‘,’ into the search field, we see a different error message:
System.Data.SqlClient.SqlException (0x80131904): Procedure or function spGetData has too many arguments specified. at System.Data.SqlClient.SqlConnection.
The mention of the stored procedure having too many arguments helps identify this technique for calling stored procedures.
With SQL we have the ability to execute more than one query in a given transaction. In this case, we just need to break out of the current exec statement and add our own statement. Remember, this doesn’t effect the execution of the spGetData stored procedure. We are looking at the ability to add new statements to the request.
Lets assume we search for this:
james@test.com’;SELECT * FROM tblUsers–
this would change our cmdText to look like:
exec spGetData’james@test.com’;SELECT * FROM tblUsers–‘
The above query will execute the spGetData stored procedure and then execute the following SELECT statement, ultimately returning 2 result sets. In many cases, this is not that useful for an attacker because the second table would not be returned to the user. However, this doesn’t mean that this makes an attack impossible. Instead, this turns our attacks more towards what we can Do, not what can we receive.
At this point, we are able to execute any commands against the SQL Server that the user has permission too. This could mean executing other stored procedures, dropping or modifying tables, adding records to a table, or even more advanced attacks such as manipulating the underlying operating system. An example might be to do something like this:
james@test.com’;DROP TABLE tblUsers–
If the user has permissions, the server would drop tblUsers, causing a lot of problems.
When calling stored procedures, it should be done using command parameters, rather than dynamically. The following is an example of using proper parameters:
conn.Open();
SqlCommand cmd = new SqlCommand();
cmd.CommandText = "spGetData";
cmd.CommandType = CommandType.StoredProcedure;
cmd.Connection = conn;
cmd.Parameters.AddWithValue("@someData", txtSearch.Text);
SqlDataAdapter adapter = new SqlDataAdapter(cmd);
DataSet ds = new DataSet();
adapter.Fill(ds);
conn.Close();
grdResults.DataSource = ds.Tables[0];
grdResults.DataBind();
The code above adds parameters to the command object, removing the ability to inject into the dynamic code.
It is easy to think that because it is a stored procedure, and the stored procedure may be safe, that we are secure. Unfortunately, simple mistakes like this can lead to a vulnerability. Make sure that you are properly making database calls using parameterized queries. Don’t use dynamic SQL, even if it is to call a stored procedure.
Potentially Dangerous Request.Path Value was Detected…
Filed under: Development, Security
I have discussed request validation many times when we see the potentially dangerous input error message when viewing a web page. Another interesting protection in ASP.Net is the built-in, on by default, Request.Path validation that occurs. Have you ever seen the error below when using or testing your application?

The screen above occurred because I placed the (*) character in the URL. In ASP.Net, there is a default set of defined illegal characters in the URL. This list is defined by RequestPathInvalidCharacters and can be configured in the web.config file. By default, the following characters are blocked:
- <
- >
- *
- %
- &
- :
- \\
It is important to note that these characters are blocked from being included in the URL, this does not include the protocol specification or the query string. That should be obvious since the query string uses the & character to separate parameters.
There are not many cases where your URL needs to use any of these default characters, but if there is a need to allow a specific character, you can override the default list. The override is done in the web.config file. The below snippet shows setting the new values (removing the < and > characters:
<httpruntime requestPathInvalidCharacters="*,%,&,:,\\"/>
Be aware that due the the web.config file being an xml file, you need to escape the < and > characters and set them as < and > respectively.
Remember that modifying the default security settings can expose your application to a greater security risk. Make sure you understand the risk of making these modifications before you perform them. It should be a rare occurrence to require a change to this default list. Understanding the platform is critical to understanding what is and is not being protected by default.
ASP.Net Insufficient Session Timeout
Filed under: Development, Security, Testing
A common security concern found in ASP.Net applications is Insufficient Session Timeout. In this article, the focus is not on the ASP.Net session that is not effectively terminated, but rather the forms authentication cookie that is still valid after logout.
How to Test
- User is currently logged into the application.
- User captures the ASPAuth cookie (name may be different in different applications).
- Cookie can be captured using a browser plugin or a proxy used for request interception.
- User saves the captured cookie for later use.
- User logs out of the application.
- User requests a page on the application, passing the previously captured authentication cookie.
- The page is processed and access is granted.
Typical Logout Options
- The application calls FormsAuthentication.Signout()
- The application sets the Cookie.Expires property to a previous DateTime.
Cookie Still Works!!
Following the user process above, the cookie still provides access to the application as if the logout never occurred. So what is the deal? The key is that unlike a true “session” which is maintained on the server, the forms authentication cookie is self contained. It does not have a server side component to stay in sync with. Among other things, the authentication cookie has your username or ID, possibly roles, and an expiration date. When the cookie is received by the server it will be decrypted (please tell me you are using protection = all) and the data extracted. If the cookie’s internal expiration date has not passed, the cookie is accepted and processed as a valid cookie.
So what did FormsAuthentation.Signout() do?
If you look under the hood of the .Net framework, it has been a few years but I doubt much has changed, you will see that FormsAuthentication.Signout() really just removes the cookie from the browser. There is no code to perform any server function, it merely asks the browser to remove it by clearing the value and back-dating the expires property. While this does work to remove the cookie from the browser, it doesn’t have any effect on a copy of the original cookie you may have captured. The only sure way to really make the cookie inactive (before the internal timeout occurs) would be to change your machine key in the web.config file. This is not a reasonable solution.
Possible Mitigations
You should be protecting your cookie by setting the httpOnly and Secure properties. HttpOnly tells the browser not to allow javascript to have access to the cookie value. This is an important step to protect the cookie from theft via cross-site scripting. The secure flag tells the browser to only send the authentication cookie over HTTPS, making it much more difficult for an attacker to intercept the cookie as it is sent to the server.
Set a short timeout (15 minutes) on the cookie to decrease the window an attacker has to obtain the cookie.
You could attempt to build a tracking system to manage the authentication cookie on the server to disable it before its time has expired. Maybe something for another post.
Understand how the application is used to determine how risky this issue may be. If the application is not used on shared/public systems and the cookie is protected as mentioned above, the attack surface is significantly decreased.
Final Thoughts
If you are facing this type of finding and it is a forms authentication cookie issue, not the Asp.Net session cookie, take the time to understand the risk. Make sure you understand the settings you have and the priority and sensitivity of the application to properly understand “your” risk level. Don’t rely on third party risk ratings to determine how serious the flaw is. In many situations, this may be a low priority, however in the right app, this could be a high priority.
F5 BigIP Decode with Fiddler
Filed under: Development, Testing
There are many tools out there that allow you to decode the F5 BigIP cookie used on some sites. I haven’t seen anything that just plugs into Fiddler if you use that for debugging purposes. One of the reasons you may want to decode the F5 cookie is just that, debugging. If you need to know what server, behind the load balancer, your request is going to to troubleshoot a bug, this is the cookie you need. I won’t go into a long discussion of the F5 Cookie, but you can read more about it I have a description here.
Most of the examples I have seen are using python to do the conversion. I looked for a javascript example, as that is what Fiddler supports in its Custom Rules but couldn’t really find anything. I got to messing around with it and put together a very rough set of functions to be able to decode the cookie value back to its IP address and Port. It sticks the result into a custom column in the Fiddler interface (scroll all the way to the right, the last column). If it identifies the cookie it will attempt to decode it and populate the column. This can be done for both response and request cookies.
To decode response cookies, you need to update the custom Fiddler rules by adding code to the static function OnBeforeResponse(oSession: Session) method. The following code can be inserted at the end of the function:
var re = /\d+\.\d+\.0{4}/; // Simple regex to identify the BigIP pattern.
if (oSession.oResponse.headers)
{
for (var x:int = 0; x < oSession.oResponse.headers.Count(); x++)
{
if(oSession.oResponse.headers[x].Name.Contains("Set-Cookie")){
var cookie : Fiddler.HTTPHeaderItem = oSession.oResponse.headers[x];
var myArray = re.exec(cookie.Value);
if (myArray != null && myArray.length > 0)
{
for (var i = 0; i < myArray.length; i++)
{
var index = myArray[i].indexOf(".");
var val = myArray[i].substring(0,index);
var hIP = parseInt(val).toString(16);
if (hIP.length < 8)
{
var pads = "0";
hIP = pads + hIP;
}
var hIP1 = parseInt(hIP.toString().substring(6,8),16);
var hIP2 = parseInt(hIP.toString().substring(4,6),16);
var hIP3 = parseInt(hIP.toString().substring(2,4),16);
var hIP4 = parseInt(hIP.toString().substring(0,2),16);
var val2 = myArray[i].substring(index+1);
var index2 = val2.indexOf(".");
val2 = val2.substring(0,index2);
var hPort = parseInt(val2).toString(16);
if (hPort.length < 4)
{
var padh = "0";
hPort = padh + hPort;
}
var hPortS = hPort.toString().substring(2,4) + hPort.toString().substring(0,2);
var hPort1 = parseInt(hPortS,16);
oSession["ui-customcolumn"] += hIP1 + "." + hIP2 + "." + hIP3 + "." + hIP4 + ":" + hPort1 + " ";
}
}
}
}
}
In order to decode the cookie from a request, you need to add the following code to the static function OnBeforeRequest(oSession: Session) method.
var re = /\d+\.\d+\.0{4}/; // Simple regex to identify the BigIP pattern.
oSession["ui-customcolumn"] = "";
if (oSession.oRequest.headers.Exists("Cookie"))
{
var cookie = oSession.oRequest["Cookie"];
var myArray = re.exec(cookie);
if (myArray != null && myArray.length > 0)
{
for (var i = 0; i < myArray.length; i++)
{
var index = myArray[i].indexOf(".");
var val = myArray[i].substring(0,index);
var hIP = parseInt(val).toString(16);
if (hIP.length < 8)
{
var pads = "0";
hIP = pads + hIP;
}
var hIP1 = parseInt(hIP.toString().substring(6,8),16);
var hIP2 = parseInt(hIP.toString().substring(4,6),16);
var hIP3 = parseInt(hIP.toString().substring(2,4),16);
var hIP4 = parseInt(hIP.toString().substring(0,2),16);
var val2 = myArray[i].substring(index+1);
var index2 = val2.indexOf(".");
val2 = val2.substring(0,index2);
var hPort = parseInt(val2).toString(16);
if (hPort.length < 4)
{
var padh = "0";
hPort = padh + hPort;
}
var hPortS = hPort.toString().substring(2,4) + hPort.toString().substring(0,2);
var hPort1 = parseInt(hPortS,16);
oSession["ui-customcolumn"] += hIP1 + "." + hIP2 + "." + hIP3 + "." + hIP4 + ":" + hPort1 + " ";
}
}
}
Again, this is a rough compilation of code to perform the tasks. I am well aware there are other ways to do this, but this did seem to work. USE AT YOUR OWN RISK. It is your responsibility to make sure any code you add or use is suitable for your needs. I am not liable for any issues from this code. From my testing, this worked to decode the cookie and didn't present any issues. This is not production code, but an example of how this task could be done.
Just add the code to the custom rules file and visit a site with a F5 cookie and it should decode the value.
A Pen Test is Coming!!
Filed under: Development, Security, Testing
You have been working hard to create the greatest app in the world. Ok, so maybe it is just a simple business application, but it is still important to you. You have put countless hours of hard work into creating this master piece. It looks awesome, and does everything that the business has asked for. Then you get the email from security: Your application will undergo a penetration test in two weeks. Your heart skips a beat and sinks a little as you recall everything you have heard about this experience. Most likely, your immediate action is to go on the defensive. Why would your application need a penetration test? Of course it is secure, we do use HTTPS. No one would attack us, we are small. Take a breath.. it is going to be alright.
All too often, when I go into a penetration test, the developers start on the defensive. They don’t really understand why these ‘other’ people have to come in and test their application. I understand the concerns. History has shown that many of these engagements are truly considered adversarial. The testers jump for joy when they find a security flaw. They tell you how bad the application is and how simple the fix is, leading to you feeling about the size of an ant. This is often due to a lack of good communication skills.
Penetration testing is adversarial. It is an offensive assessment to find security weaknesses in your systems. This is an attempt to simulate an attacker against your system. Of course there are many differences, such as scope, timing and rules, but the goal is the same. Lets see what we can do on your system. Unfortunately, I find that many testers don’t have the communication skills to relay the information back to the business and developers in a way that is positive. I can’t tell you how may times I have heard people describe their job as great because they get to come in, tell you how bad you suck and then leave. If that is your penetration tester, find a new one. First, that attitude breaks down the communication with the client and doesn’t help promote a secure atmosphere. We don’t get anywhere by belittling the teams that have worked hard to create their application. Second, a penetration test should provide solid recommendations to the client on how they can work to resolve the issues identified. Just listing a bunch of flaws is fairly useless to a company.
These engagements should be worth everyone’s time. There should be positive communication between the developers and the testing team. Remember that many engagements are short lived so the more information you can provide the better the assessment you are going to get. The engagement should be helpful. With the right company, you will get a solid assessment and recommendations that you can do something with. If you don’t get that, time to start looking at another company for testing. Make sure you are ready for the test. If the engagement requires an environment to test in, have it all set up. That includes test data (if needed). The testers want to hit the ground running. If credentials are needed, make sure those are available too. The more help you can be, the more you will benefit from the experience.
As much as you don’t want to hear it, there is a very high chance the test will find vulnerabilities. While it would be great if applications didn’t have vulnerabilities, it is fairly rare to find them. Use this experience to learn and train on security issues. Take the feedback as constructive criticism, not someone attacking you. Trust me, you want the pen testers to find these flaws before a real attacker does.
Remember that this is for your benefit. We as developers also need to stay positive. The last thing you want to do is challenge the pen testers saying your app is not vulnerable. The teams that usually do that are the most vulnerable. Say positive and it will be a great learning experience.
Bounties For Fixes
It was just recently announced that Google will pay for open-source code security fixes (http://www.computerworld.com/s/article/9243110/Google_to_pay_for_open_source_code_security_fixes). Paying for stuff to happen is nothing new, we have seen Bug Bounty programs popping up in a lot of companies. The idea behind the bug bounty is that people can submit bugs they have found and then possibly get paid for that bug. This has been very successful for some large companies and some bug finders out there.
The difference in this new announcement is that they are paying for people to apply fixes to some open source tools that are widely used. I personally think this is a good thing because it will encourage people to actually start fixing some of the issues that exist. Security is usually bent on finding vulnerabilities, which doesn’t really help fix security at all. It still requires the software developers to implement some sort of change to get that security hole plugged. Here, we see that the push to fix the problem is now being rewarded. This is especially true in open-source projects as many of the people that work on these projects do so voluntarily.
Is there any concern though that this process could be abused? The first thought that comes to mind is people working together where one person plants the bug and the other one fixes it. Not sure how realistic that is, but I am sure there are people thinking about it. What could possibly be more challenging is verifying the fixes. What happens if someone patches something, but they do it incorrectly? Who is testing the fix? How do they verify that it is really fixed properly? If they find later that the fix wasn’t complete, does the fixer have to return the payment? There are always questions to be answered when we look at a new program like this. I am sure that Google has thought about this before rolling it out and I really hope the program works out well. it is a great idea and we need to get more people involved in helping fix some of these issues.
Your Passwords Were Stolen: What’s Your Plan?
Filed under: Development, Security
If you have been glancing at many news stories this year, you have certainly seen the large number of data breaches that have occurred. Even just today, we are seeing reports that Drupal.org suffered from a breach (https://drupal.org/news/130529SecurityUpdate) that shows unauthorized access to hashed passwords, usernames, and email addresses. Note that this is not a vulnerability in the CMS product, but the actual website for Drupal.org. Unfortunately, Drupal is just the latest to report this issue.
In addition to Drupal, LivingSocial also suffered a huge breach involving passwords. LinkedIn, Evernote, Yahoo, and Name.com have also joined this elite club. In each of these cases, we have seen many different formats for storing the passwords. Some are using plain text (ouch), others are actually doing what has been recommended and using a salted hash. Even with a salted hash, there are still some issues. One, hashes are fast and some hashes are not as strong as others. Bad choices can lead to an immediate failure in implementation and protection.
Going into what format you should store your passwords in will be saved for another post, and has been discusses heavily on the internet. It is really outside the scope of this post, because in this discussion, it is already too late for that. Here, I want to ask the simple question of, “You have been breached, What do you do?”
Ok, Maybe it is not a simple question, or maybe it is. Most of the sites that have seen these breaches are fairly quick to force password resets by all of their users. The idea behind this is that the credentials were stolen, but only the actual user should be able to perform a password reset. The user performs the reset, they have new credentials, and the information that the bad guy got (and everyone else that downloads the stolen credentials) are no good. Or maybe not?? Wait.. you re-use passwords across multiple sites? Well, that makes it more interesting. I guess you now need to reset a bunch of passwords.
Reseting passwords appears to be the standard. I haven’t seen anyone else attempt to do anything else, if you have please share. But what else would work? You can’t just change the algorithm to make it stronger.. the bad guy has the password. Changing the algorithm doesn’t change that fact and they just log in using a stronger algorithm. I guess that won’t work. Might be nice to have a mechanism to upgrade everyone to a stronger algorithm as time goes on though.
So if resetting passwords in mass appears to work and is the standard, do you have a way to do it? if you got breached today, what would you need to do to reset everyone’s password, or at least force a password reset on all users? There are a few options, and of course it depends on how you actually manage user passwords.
If you have a password expiration field in the DB, you could just set all passwords to have expired yesterday. Now everyone will be presented with an expired password prompt. The problem with this solution is if an expired password just requires the old password to set the new password. It is possible the bad guy does this before the actual user. Oops.
You could Just null out or put in a 0 or some false value into all of the password fields. This only works for encrypted or hashed passwords.. not clear text. This could be done with a simple SQL Update statement, just drop that needless where clause ;). When a user goes to log in, they will be unsuccessful because when the password they submit is encrypted or hashed, it will never match the value you updated the field to. This forces them to use the forgot password field.
You could run a separate application that resets everyone password like the previous method, it just doesn’t run a DB Update directly on the server. Maybe you are a control freak as to what gets run against the servers and control that access.
As you can see, there are many ways to do this, but have you really given it any thought? Have you written out your plan that in the event your site gets breached like these other sites, you will be able to react intelligently and swiftly? Often times when we think of incidence response, we think of stopping the attack, but we also have to think about how we would protect our users from future attacks quickly.
These ideas are just a few examples of how you can go about this to help provoke you and your team to think about how you would do this in your situation. Every application is different and this scenario should be in your IR plan. If you have other ways to handle this, please share with everyone.
Follow Us


